Jednorozměrný statistický (též výběrový) soubor (viz kapitolu "Základní pojmy matematické statistiky") obsahuje hodnoty jediného argumentu (sledovaného znaku). Následující text se výhradně zabývá nejčastějším případem, kdy argumentem je číselná hodnota; sledovaný znak je tedy kvantitativní.
Dále bude X = {x1, x2, ... , xn} značit nějaký jednorozměrný statistický (výběrový) soubor rozsahu n.
Příklad: V rámci environmentálních dopadů na genetické schopnosti flóry, konkrétně reprodukčních schopností jedle, byla zkoumána semena jedlí v delší časové řadě. Následující tabulka obsahuje datový element výzkumu - náhodně vybraných 400 vah semen jedlí v [g] v jednom vegetačním období jedné konkrétní oblasti:
| 4.717 | 4.411 | 4.549 | 4.432 | 4.186 | 4.402 | 4.529 | 4.841 | 4.501 | 4.384 | 4.451 | 4.343 | 4.599 | 4.230 | 4.407 | 4.149 |
| 4.471 | 4.169 | 4.465 | 4.596 | 4.235 | 4.534 | 4.328 | 4.393 | 4.458 | 4.220 | 4.431 | 4.570 | 4.618 | 4.225 | 4.792 | 4.450 |
| 4.615 | 4.092 | 4.731 | 4.293 | 4.456 | 4.620 | 4.369 | 4.749 | 4.377 | 4.816 | 4.477 | 4.254 | 4.343 | 4.586 | 4.378 | 4.588 |
| 4.508 | 4.510 | 4.416 | 4.626 | 4.990 | 4.459 | 4.574 | 4.601 | 4.334 | 4.380 | 4.658 | 4.713 | 4.698 | 4.627 | 4.579 | 4.634 |
| 4.461 | 4.489 | 4.486 | 4.712 | 4.836 | 4.377 | 4.439 | 4.377 | 4.791 | 4.569 | 4.258 | 4.099 | 4.200 | 4.479 | 4.482 | 4.577 |
| 4.837 | 4.443 | 4.049 | 4.409 | 4.523 | 4.601 | 4.325 | 4.461 | 4.347 | 4.714 | 4.497 | 4.332 | 4.679 | 4.768 | 4.453 | 4.662 |
| 4.427 | 4.999 | 4.697 | 4.392 | 4.450 | 4.709 | 4.628 | 4.737 | 4.414 | 4.793 | 4.577 | 4.536 | 4.014 | 4.901 | 4.515 | 4.471 |
| 4.726 | 4.729 | 4.379 | 4.579 | 4.356 | 4.374 | 4.640 | 4.531 | 4.382 | 4.654 | 4.297 | 4.309 | 4.057 | 4.584 | 4.911 | 4.275 |
| 4.528 | 4.527 | 4.600 | 4.522 | 4.392 | 4.674 | 4.745 | 4.751 | 4.225 | 4.645 | 4.318 | 4.187 | 4.657 | 4.598 | 4.346 | 4.523 |
| 4.339 | 4.220 | 4.701 | 4.340 | 4.489 | 4.386 | 4.664 | 4.519 | 4.264 | 4.591 | 4.796 | 4.430 | 4.586 | 4.708 | 4.583 | 4.493 |
| 4.745 | 4.579 | 4.462 | 4.714 | 4.684 | 4.649 | 4.919 | 4.552 | 4.290 | 4.393 | 4.817 | 4.799 | 4.195 | 4.360 | 4.716 | 4.191 |
| 4.475 | 4.908 | 4.474 | 4.694 | 4.277 | 4.147 | 4.403 | 4.470 | 4.250 | 4.441 | 4.692 | 4.650 | 4.344 | 4.241 | 4.417 | 4.606 |
| 4.481 | 4.510 | 4.238 | 4.512 | 4.557 | 4.061 | 4.573 | 4.440 | 4.839 | 4.386 | 4.928 | 4.279 | 4.638 | 4.430 | 4.472 | 4.490 |
| 4.159 | 4.283 | 4.325 | 4.721 | 4.575 | 4.356 | 4.618 | 4.434 | 4.595 | 4.607 | 4.582 | 4.500 | 4.396 | 4.329 | 4.174 | 4.297 |
| 4.915 | 4.360 | 4.339 | 4.407 | 4.511 | 4.492 | 4.502 | 4.562 | 4.538 | 4.498 | 4.607 | 4.746 | 4.529 | 4.325 | 4.758 | 4.514 |
| 4.527 | 4.491 | 4.617 | 4.412 | 4.648 | 4.577 | 4.387 | 4.681 | 4.617 | 4.334 | 4.547 | 4.398 | 4.462 | 4.996 | 4.482 | 4.508 |
| 4.501 | 4.579 | 4.258 | 4.615 | 4.406 | 4.595 | 4.086 | 4.446 | 4.712 | 4.193 | 4.790 | 4.536 | 4.425 | 4.599 | 4.723 | 4.453 |
| 4.397 | 4.625 | 4.024 | 4.561 | 4.455 | 4.470 | 4.367 | 4.656 | 4.480 | 4.483 | 4.430 | 4.466 | 4.571 | 4.569 | 4.689 | 4.690 |
| 4.795 | 4.415 | 4.379 | 4.642 | 4.839 | 4.761 | 4.543 | 4.596 | 4.451 | 4.531 | 4.260 | 4.790 | 4.430 | 4.837 | 4.861 | 4.434 |
| 4.381 | 4.275 | 4.199 | 4.640 | 4.737 | 4.299 | 4.521 | 4.635 | 4.001 | 4.771 | 4.186 | 4.473 | 4.425 | 4.640 | 4.437 | 4.657 |
| 4.431 | 4.514 | 4.461 | 4.779 | 4.283 | 4.583 | 4.349 | 4.414 | 4.628 | 4.296 | 4.679 | 4.527 | 4.293 | 4.422 | 4.260 | 4.637 |
| 4.316 | 4.621 | 4.738 | 4.554 | 4.361 | 4.342 | 4.688 | 4.563 | 4.236 | 4.507 | 4.502 | 4.333 | 4.538 | 4.290 | 4.503 | 4.435 |
| 4.825 | 4.456 | 4.592 | 4.854 | 4.512 | 4.316 | 4.846 | 4.527 | 4.991 | 4.727 | 4.569 | 4.333 | 4.433 | 4.467 | 4.429 | 4.631 |
| 4.718 | 4.598 | 4.446 | 4.920 | 4.778 | 4.734 | 4.371 | 4.376 | 4.273 | 4.265 | 4.147 | 4.388 | 4.307 | 4.509 | 4.737 | 4.807 |
| 4.732 | 4.328 | 4.330 | 4.294 | 4.440 | 4.712 | 4.927 | 4.348 | 4.374 | 4.575 | 4.690 | 4.497 | 4.535 | 4.111 | 4.403 | 4.683 |
Tab 5.1: Experimentálně zjištěné váhy semen jedle
Argumentem (sledovaným znakem) je tedy váha semene jedle v [g]. Rozsah souboru je 400. Rozměr souboru je 1.
Výběrový průměr x' je číselně roven aritmetickému průměru. Je tedy
x' = ( ĺ xi ) / n
kde n je rozsah souboru.
Příklad: Výběrový průměr souboru s vahami semen jedle je (4,717 + 4,411 + ... + 4,403 + 4,683) / 400 = 1802,521 / 400 = 4,50629.
Výběrový rozptyl s2 je číselně roven průměrné kvadratické odchylce od průměru, tj.
s2 = ĺ (xi-x')2 / n
kde x' je shora definovaný výběrový průměr. Uvedený vztah lze psát také jako
s2 = ( ĺ xi2 - (ĺxi)2/n ) / n
přičemž tento druhý tvar je lépe využitelný při rutinních výpočtech (rozptyl se spočte jediným průchodem).
Příklad: Výběrový rozptyl souboru s
vahami semen jedle je podle prvního vztahu ((4,717-4,50629)2
+ (4,411-4,50629)2 + ... + (4,403-4,50629)2 +
(4,683-4,50629)2) / 400 = 0,036676.
K hodnotě rozptylu lze dojít také takto: Součet xi spočtený
při zjišťování průměru je 1802,521. Součet xi2
je 8137,375. Počet je 400. Rozptyl je tedy podle druhého vztahu roven
(8137,366 - 1802,5202/400) / 400 = 0,036676.
Medián xm je podle definice 50%-kvantil, tj. hodnota, "pod kterou" leží nejvýš polovina hodnot souboru a "nad kterou" leží nejvýš polovina hodnot souboru. Při jeho určení se v praxi postupuje následovně:
Soubor se uspořádá podle velikosti. Označme takto uspořádaný soubor Y = {y1, y2, ... , yn}; každé yi je tedy nějaké xk.
Nechť m je celá část podílu n/2: m = [n/2]. Je-li n sudé, je n=2.m, je-li n liché, je n=2.m+1.
Je-li n liché, je mediánem hodnota ym+1. Je-li n sudé, je mediánem hodnota (ym+ym++)/2.
Příklad: Medián souboru s vahami semen jedle se zjistí postupem popsaným výše. Nejprve se hodnoty seřadí podle velikosti. Získá se následující posloupnost hodnot:
| Pořadí | 1. | 2. | ... | 199. | 200. | 201. | 202. | ... | 399. | 400. |
| Hodnota | 4,001 | 4,014 | ... | 4,498 | 4,500 | 4,501 | 4,501 | ... | 4,996 | 4,999 |
Tab. 5.2: Tabulka pro výpočet mediánu
"Polovinou" souboru je hranice mezi 200.tým a 201.ním prvkem (prvků je sudý počet). Medián je tedy polovina mezi 4,500 a 4,501, tj. 4,5005.
Dolní a horní kvartil xD a xH jsou podle definice 25%-kvantil a 75%-kvantil, tj. hodnoty, "pod kterými" leží nejvýš čtvrtina resp. tři čtvrtiny hodnot souboru a "nad kterými" leží nejvýš tři čtvrtiny resp. čtvrtina hodnot souboru. Při určení dolního kvartilu se v praxi postupuje následovně:
Soubor se uspořádá podle velikosti. Označme takto uspořádaný soubor Y = {y1, y2, ... , yn}; každé yi je tedy nějaké xk.
Nechť m je celá část podílu n/2: m = [n/2]. Je-li n sudé, je n=2.m, je-li n liché, je n=2.m+1.
Označme symbolem Z množinu Z = {y1, y2, ... , ym}, tedy "dolní polovinu" uspořádané množiny X bez případného "prostředního" prvku.
Nechť k je celá část podílu m/2: k = [m/2]. Je-li m sudé, je m=2.k, je-li m liché, je m=2.k+1.
Je-li m liché, je dolním kvartilem hodnota yk. Je-li m sudé, je dolním kvartilem hodnota yk+1 - 0,25.(yk+1-yk).
Příklad: Dolní kvartil souboru s vahami semen jedle se zjistí postupem popsaným výše. Nejprve se hodnoty seřadí podle velikosti. Získá se posloupnost hodnot, jejíž důležitá část je v následující tabulce:
| Pořadí | 1. | 2. | ... | 100. | 101. | ... | 199. | 200. |
| Hodnota | 4,001 | 4,014 | ... | 4,378 | 4,379 | ... | 4,498 | 4,500 |
Tab. 5.3: Tabulka pro výpočet dolního kvartilu
Počet prvků souboru je 400, tedy sudé číslo.
Polovina prvků je 200, čtvrtina prvků je 100, vše celá čísla. Je
tedy podle bodu 4: k=100, k+1=101. Podle bodu 5 je dolní kvartil roven
4,379 - 0,25 . (4,739 - 4,738) = 4,37875.
Analogicky při určení horního kvartilu se postupuje následovně:
Soubor se uspořádá podle velikosti. Označme takto uspořádaný soubor Y = {y1, y2, ... , yn}; každé yi je tedy nějaké xk.
Nechť m je celá část podílu n/2: m = [n/2]. Je-li n sudé, je n=2.m, je-li n liché, je n=2.m+1.
Označme symbolem Z množinu Z = {ym+1, ym+2, ... , yn}, tedy "horní polovinu" uspořádané množiny X bez případného "prostředního" prvku.
Nechť k je celá část podílu m/2: k = [m/2]. Je-li m sudé, je m=2.k, je-li m liché, je m=2.k+1.
Je-li m liché, je horním kvartilem hodnota yk. Je-li m sudé, je dolním kvartilem hodnota yk+1 - 0,75.(yk+1-yk).
Příklad: Horní souboru s vahami semen jedle se zjistí postupem popsaným výše. Nejprve se hodnoty seřadí podle velikosti. Získá se posloupnost hodnot, jejíž důležitá část je v následující tabulce:
| Pořadí | 201. | 202. | ... | 300. | 301. | ... | 399. | 400. |
| Hodnota | 4,501 | 4,501 | ... | 4,634 | 4,635 | ... | 4,996 | 4,999 |
Tab. 5.4: Tabulka pro výpočet horního kvartilu
Počet prvků souboru je 400, tedy sudé číslo.
Polovina prvků je 200, tři čtvrtiny prvků je 300, vše celá čísla.
Je tedy podle bodu 4: k=300, k+1=301. Podle bodu 5 je horní kvartil
roven
4,635 - 0,75 . (4,635 - 4,634) = 4,63425.
Zápis dat souboru, který obsahuje jednotlivé hodnoty (tak, jako např. tabulka experimentálně zjištěných vah semen jedle v příkladu nahoře), je někdy objemný - zvláště v případech dat, v nichž se hodnoty opakují. V uvedeném příkladu se např. hodnota 4,430 opakuje 4x - stejně jako hodnoty 4,527 a 4,579. Osm jiných hodnot se opakuje 3x, 74 jiných hodnot 2x a zbývajících 148 hodnot je v souboru jen jednou. Data namísto prostého vyjmenování lze zapsat do tzv. četnostní nebo také frekvenční tabulky s obsahem a formátem zřejmým z následujícího příkladu:
Příklad: Četnostní (frekvenční) tabulka shora uvedených experimentálně zjištěných vah semen jedle může mít následující začátek:
| Hodnota | Četnost (frekvence) výskytu hodnoty |
| 4,430 | 4x |
| 4,527 | 4x |
| 4,579 | 4x |
| 4,325 | 3x |
| ... | ... |
Tab. 5.5: Četnostní tabulka dat
U mnohých souborů - právě jako v příkladu semen jedlí - se sice o něco zmenší počet (nyní již neopakujících se hodnot), ale ne o moc. V příkladu nahoře je místo 400 (i opakujících se hodnot) hodnot 301 (ale neopakujících se). To je sice úspora 25%, ale stále je 300 hodnot špatně celkově hodnotitelných.
Případ semen jedlí navíc ukazuje na velmi podstatný v praxi uplatňovaný aspekt. Mějme neustále na paměti, že základní statistický soubor tvoří náhodný výběr ze základního souboru. Proto i hodnoty jsou náhodné s nějakým rozložením. Jestliže je rozlišení 0,001 [mm], v podstatě se stejnou pravděpodobností se místo hodnoty 4,521 mohla ve výběru ocitnout hodnota 4,520 nebo 4,522. V praxi se tedy obvykle stanoví nějaký interval, který je z hlediska rozlišení zkoumaného problému významný. U semen jedlí by to mohlo být např. 0,050 [mm] - tedy 50tinásobek minimálního rozlišení. Označme tuto hodnotu d.
Pak lze interval <xmin,xmax> "překrýt" intervalem <a0,ak> takovým, že a0 Ł xmin, xmax Ł ak a (ak-a0)=d.k - interval <a0,ak> je tedy možno rozložit na třídy, z nichž každá je intervalem tvaru <a0+(i-1).d , a0+i.d) pro i=1, 2, ... , k (poslední interval není polootevřený, ale uzavřený).
Poznámka: Ze statistického hlediska je jedno, zda volíme třídy tvaru <ai,ai+1) nebo tvaru (ai,ai+1> - v literatuře i v praxi se používá obou způsobů. Důležité je, že každá statistická jednotka padne právě do jednoho intervalu.
Příklad: Interval dat ze shora uvedeného příkladu jedlových semen je <4,001,4,999>. Pro d=0,050 může být "překrývající" interval např. <4,000,5,000> a jednotlivé podintervaly tvořící rozklad po řadě <4,000,4,050), <4,505,4,100), ... , <4,950,5,000>.
Četnostní (frekvenční) tabulka tříd pak udává, kolik hodnot výběrového souboru padne do toho kterého třídního intervalu.
Příklad: Pro shora uvedený rozklad intervalu <4,5> má četnostní (frekvenční) tabulka tříd tvar
| i | ai-1 | ai | Četnost |
|---|---|---|---|
| 1 | 4.00 | 4.05 | 4 |
| 2 | 4.05 | 4.10 | 5 |
| 3 | 4.10 | 4.15 | 4 |
| 4 | 4.15 | 4.20 | 10 |
| 5 | 4.20 | 4.25 | 11 |
| 6 | 4.25 | 4.30 | 23 |
| 7 | 4.30 | 4.35 | 28 |
| 8 | 4.35 | 4.40 | 32 |
| 9 | 4.40 | 4.45 | 39 |
| 10 | 4.45 | 4.50 | 43 |
| 11 | 4.50 | 4.55 | 41 |
| 12 | 4.55 | 4.60 | 40 |
| 13 | 4.60 | 4.65 | 31 |
| 14 | 4.65 | 4.70 | 21 |
| 15 | 4.70 | 4.75 | 28 |
| 16 | 4.75 | 4.80 | 15 |
| 17 | 4.80 | 4.85 | 11 |
| 18 | 4.85 | 4.90 | 2 |
| 19 | 4.90 | 4.95 | 8 |
| 20 | 4.95 | 5.00 | 4 |
Tab. 5.6: Četnostní tabulka tříd
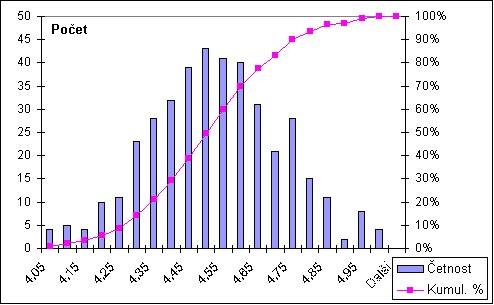
Názorným grafickým znázorněním rozložení četnosti ve výběrovém souboru je četnostní histogram. Na osu X je vynášena horní hranice třídy, na osu Y četnost hodnot výběrového souboru v intervalu. Jde o sloupcový graf posledních dvou sloupců předchozí tabulky
Příklad: Četnostní histogram velikostí semen jedle z příkladu dat shora s třídami 0,050 [mm] ukazuje následující obrázek:
Obr. 5.1: Četnostní histogram
Plynulá křivka na obrázku vypovídá o tzv. kumulativních četnostech: kolik hodnot výběrového souboru je menších než uvedená hranice třídy. Na grafu jsou kumulativní četnosti vyjádřeny v procentech; je tedy možno alespoň přibližně zkontrolovat polohy dolního kvartilu (X pro četnost do 25%), mediánu (do 50%) a horního kvartilu (do 75%).
Pro názornost byla do dalšího obrázku přidána křivka aproximující rovnici normální rozdělení pro data z příkladu: Je zřejmé, že data s velkou pravděpodobností nají normální rozdělení.
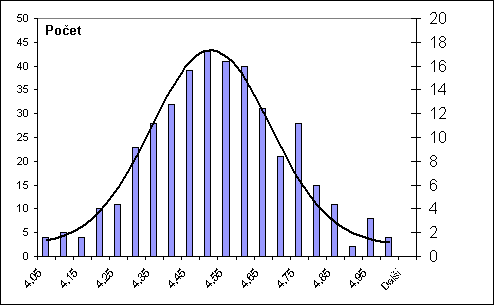
Obr. 5.2: Četnostní histogram s křivkou normálního rozdělení
Velmi populární (protože jednoduchý a přitom s rozumnou vypovídací schopností) je tzv. krabicový graf. Jeho nejjednodušší podoba vypovídá o kvantilech na úrovni 0%, 25%, 50%, 75% a 100%, tedy o minimu, dolním kvartilu, mediánu, horním kvartilu a maximu:
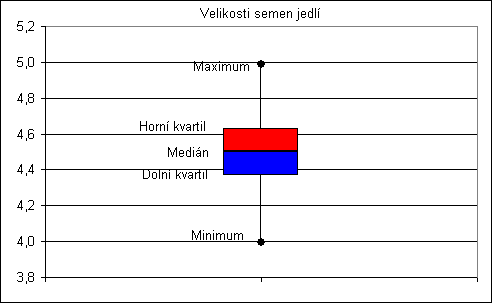
Obr. 5.3: Příklad krabicového grafu
Na krabicovém grafu jsou podstatné nejen polohy popsaných hodnot, ale i výšky jednotlivých částí grafu. Je vhodné si uvědomit, že např. v intervalu vymezeném dolní úsečkou (tj. od minima k dolnímu kvartilu) se nachází 25% všech dat výběrového souboru. Protože dolní úsečka je vyšší než výška spodního (v barvě modrého) obdélníka, mají data od minima k dolnímu kvartilu větší rozptyl než data od dolního kvartilu k mediánu - těch je také 25%!